This is the first of series of articles, collaboratively written by data and solution architects at Myers-Holum, Inc., PRA Health Sciences, and Google, describing an architectural framework for conversions of data warehouses from Teradata to the Google Cloud Platform. The series will explore common architectural patterns for Teradata data warehouses and outline best-practice guidelines for porting these patterns to the Google Cloud Platform toolset.
David Chu and Knute Holum, Myers-Holum, Inc.
Michael Trolier, Ph.D., PRA Health Sciences
June, 2018
The Opportunity: Modern cloud infrastructure offers a compelling opportunity to reimagine demanding data applications. Large data warehouses, long constrained by prior technology, can be good candidates for migration to the cloud. Google Cloud Platform offers a suite of fully-managed, elastically-scalable database services suitable for re-platforming large data warehouses for enhanced performance at reduced cost and complexity.
⇒ Begin with this: understand what you have
If what you have is an enterprise data warehouse implemented on a Teradata platform, quite likely it’s big, and it’s complex. It may also be expensive. There may be multiple architectural layers with hundreds or thousands of tables, relationships, and data transformations, representing a very significant investment of intellectual effort. If you are fortunate, the architectural patterns are evident and consistent, and the business and technical requirements that drove the implementation are well-known and clearly documented. You know whether those requirements still apply, or whether they have been superseded. Understand and respect the scale of what you have.
Consider where your data warehouse might come to reside. Google Cloud Platform supports several SQL-capable data services: Cloud SQL, Cloud Spanner, and BigQuery, each of which offers capabilities relevant to a data warehousing environment. BigQuery in particular can be very fast at remarkable scale, though it has architectural features that differ significantly from a conventional RDBMS platform.
In this series of articles, we’ll walk through the details of getting from here to there.
⇒ Know what you’re in for
There’s no getting around it: you’re in for a pretty big job. Whether it’s pretty big and manageable or daunting depends mostly on how well you understand your current data warehouse. If you’re fortunate, your current system is well-documented, you have mature data management practices, and you have strong institutional knowledge of the requirements, structure, and evolution of the current system. Plan to spend time on architecture and planning up front. Plan an incremental conversion, testing carefully at each stage. Plan to run the current and migrated systems in parallel for a period of time commensurate with your need for cross-validation.
⇒ Dust off your reference architecture before migrating to the cloud.
If you are fortunate, your data warehouse has a foundation – an intentional alignment between business requirements and information management best practices. This bedrock design, expressed independently of technology or vendor, is your reference data architecture. It informed the selection of your technology stack – including the Teradata platform, and your ETL/ELT, business intelligence, and data analysis toolsets – and provided the roadmap for implementing the data warehouse using those tools.
If you are fortunate, uncovering this architecture is not an archeological exercise. Examples:
There may have been a business requirement to retain and access all historical data as they appeared at the time they were originally recorded. Following best practices:
- you implemented effective dates on all data warehouse tables to support point-in-time access.
There may have been a business requirement to track all financial metrics back to the source transaction. Following best practices:
- you implemented data lineage tracking columns on all data warehouse tables so any reported metric could be traced back to the source transaction(s) it was computed from.
Once you understand the reference architecture that underlies your current implementation, ask whether it still applies. Make no mistake: migrating a large-scale data warehouse to the cloud will require some effort, and you want to end up where you need to be now (or as far into the future as your crystal ball reveals), not where you needed to be a decade or two ago. By returning to your reference data architecture and the business requirements driving it, you can:
- weed out business requirements – and any related architectural and implementation components – that are no longer needed;
- recognize business requirements that are not well met by the Teradata implementation;
- take advantage of Google Cloud Platform technology features that might be easier to implement than the current Teradata implementation.
There’s more to migrating to the cloud than mapping technology features; you need more than a forklift. A conversion approach that fails to recognize that key architectural requirements may have changed over the years, and therefore does not bother to define a future-state reference data architecture, will likely not be successful.
⇒ Understand and validate the key reference data architecture components.
Like a good birthday cake, most data warehouses – implemented on Teradata or otherwise – have three architectural layers. Unlike most cakes, these layers are logical in nature and distinct by design, with each serving a specific role within the warehouse. The three layers are:
- a source data capture layer;
- a central (or “active”) data warehouse layer; and
- an end-user consumption (or semantic) layer.
In some Teradata data warehouse implementations, only one of these layers (the active data warehouse) exists as a physical datastore.
As you consider migrating your data warehouse to the cloud, you must ask the same questions for each layer independently: what business and technical requirements influenced the existing implementation; how (and how well) does the implementation satisfy the requirements; whether the requirements still apply; and how you should implement that layer going forward to Google Cloud. The extent to which you created clear architectural guidelines and associated development standards around each layer will be a large factor in the ease of converting your Teradata implementation. Even so, some implementation patterns will port far more readily than others; there are some cases where significant redesign may be required.
Let’s consider each architectural layer in turn.
Source data capture layer
This is the first hop; your existing Teradata implementation first captures data from various sources of record, then either stages it or loads it directly to your data warehouse. There are a variety of approaches for each process; your implementation may use a consistent style or a mix of techniques. Data capture might occur via:
- Pull – you extract data directly from the source of record by accessing its database (or mirror, replica, or database log) on some periodic basis;
- Push – you get a periodic set of data from the source of record (e.g. via flat files) and do not access its database; or
- Stream – you get an episodic or real-time (not periodic) feed of data via a streaming interface (message, queue, etc).
Your Teradata implementation will then land the data somewhere, typically via one or more of these approaches:
- You land it in a file system for later use by a Teradata utility (FASTLOAD, TPT);
- You stage it in work or temporary tables in a relational database (or NoSQL or Hadoop);
- You land it in permanent database tables so that source data is retained close to its original format; or
- You use ETL and don’t land it all, but rather transform it in-flight to its final data warehouse target tables.
Business requirements influence the implementation style of the source data capture layer. Typical considerations are the required latency – how quickly changes in sources must be reflected in the data warehouse – and requirements to trace lineage and retain source data. Technical constraints are also important. On the data capture side, the capture strategy (pull, push, stream) is typically dictated at least in part by the capabilities of the source application. The choice of landing strategy is typically influenced by the capabilities of the tool or tools that will consume the landed source data.
One of the best ways to avoid unnecessary complication in your data warehouse conversion is to keep most of your current source data capture processes in place. While a capture strategy (e.g. push) for a specific source of record may not meet the current business need (they want to stream for example), a change to this strategy should be avoided unless it’s implemented on the Teradata side first. How would you perform side-by-side conversion validation if the captured source data are not the same?
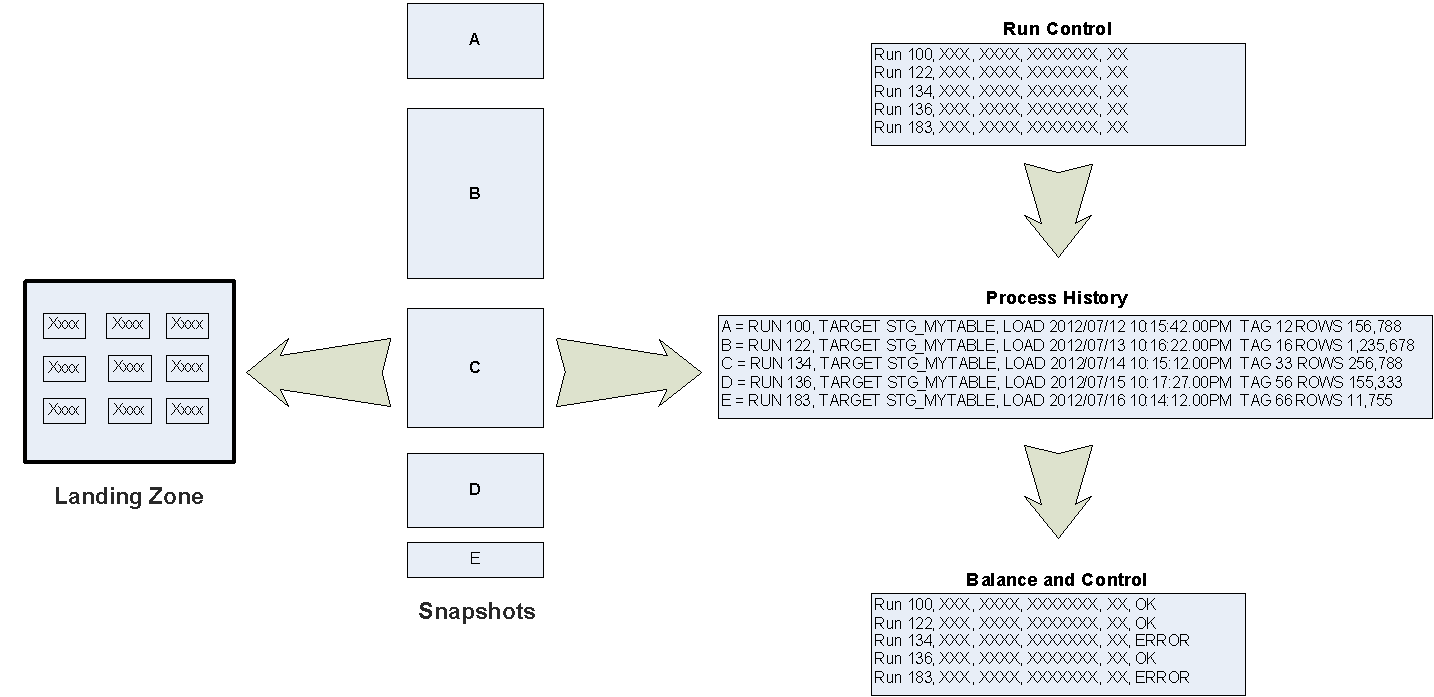
After you’ve considered data capture, you’ll want to characterize how the captured data are landed, and whether your implementation includes reference data architecture components that support a unified landing model regardless of the capture method and source of record. For example, MHI uses a unified landing model we typically call “landing zone”, and we persist that model in a relational database and distributed storage. All data capture activities target the “landing zone”, and control processes manage the accessibility and lifespan of slices of captured data.
It is important to realize that this initial landing of data is the point where you want the data copied to the Google cloud. A standardized approach will provide operational benefit. Note that this standardized approach is essentially a data lake, and thus would provide analytical benefit, particularly if you have an experienced data mining / data analysis / data science team accustomed to accessing a data lake.
The landed data typically anchor the beginning of data lineage – the tracing of data elements from the source through the warehouse’s architectural layers and transformations. This is frequently a key business requirement and is foundational for effectively validating warehouse data. A typical MHI “landing zone” table for a batch (ETL) process would satisfy this requirement by appending a number of “ETL” attributes that support process and lineage tracking. Representative attributes might carry identifiers to track individual rows, session execution, and workflow execution; these values would then propagate to downstream architectural layers. This allows each data element to be tracked unambiguously through the warehouse.
If you are using a variety of landing methods (work tables, flat files, etc.) without regard to any architectural standardization, your conversion becomes more complicated, and the difficulty of tracing data lineage increases significantly.
At the end of this analysis of your source data capture layer, you will create a catalog for the layer, enumerating source systems, data volumes, latency requirements, architectural patterns, and source capture and landing approaches. Each variation will require a specific conversion approach.
Central Data Warehouse Layer
The primary business requirement for this architectural layer is integration – preparing and reconciling information from disparate sources in an internally-consistent way to support global access and analysis. There has been an active conversation in the warehousing community for many years about the “best” way to achieve this goal, with convictions of near-religious fervor evident from prominent voices. Fortunately, we don’t need to identify a “best” approach; we simply need to understand the common design idioms, and know how to use the Google Cloud Platform toolset to support each.
Among Teradata implementations, two architectural styles are most common. In the first, commonly referred to as an “Operational Data Store” (ODS), the data warehouse is modeled after the system of record. Warehouse tables look like the source system tables – and there are probably as many variations of the representation of each data entity (e.g. a reservation or a travel itinerary) as there are source systems. The layer may support versioning (the time series of changes) through the addition of effective date attributes, a sequence number, and a current-record indicator. The layer may further support architectural controls through the addition of lineage- and/or process-tracking attributes. This architectural style typically relies on a robust semantic layer to achieve significant integration of data from separate sources.
In the second common Teradata architectural pattern, the data warehouse is modeled after a canonical industry model, whether purchased (e.g. a Teradata industry data model), based on a design pattern (e.g. Silverston) or created in-house. This style is often referred to as a Teradata “Active Data Warehouse”. In this case, the data warehouse tables follow a canonical model designed to support current- and future-state business requirements to the greatest extent possible. Versioning of data is typically supported robustly. The schema is typically highly normalized (e.g. 3rd-normal-form), and the consumption model relies on the power of the Teradata platform to allow downstream applications to directly and efficiently access the data warehouse while preserving a single copy of the data. Those downstream applications are typically SQL access (SQL Assistant), BI applications or ELT/ETL processes that feed downstream applications. This is the style of the Inmon “Corporate Information Factory”.
Two additional architectural patterns are encountered rather rarely on Teradata; we include them here for completeness. Both would be robustly supported by the Teradata architecture. One is the Kimball “Bus Architecture”, in which the data warehouse is modeled as a series of data marts (star schemas) integrated via conformed dimensions. The other is the “Data Vault”, in which data and relationships are cast into a design pattern based on “hubs”, “satellites” and “links”.
For all their differences, a common feature of these various architectural patterns is the need to handle CRUD (create-read-update-delete) data and manage versioning of information, to satisfy the common business requirement to faithfully represent historical data. This will be a key consideration for any conversion of a data warehouse to Google Cloud Platform.
We will cover conversion approaches for each of these architectural patterns in future articles.
Right now, though, we’ll return to business requirements. The data-architecture style you choose for your Google Cloud data warehouse implementation will be a key decision, and it is important to look at business requirements that might dictate one style over another.
Key reasons businesses model their data warehouse like the source of record:
- It is a more agile (bottom-up) approach, easiest to model and develop.
- The organization is frequently changing operational systems (hyper-growth mode).
- The organization has compartmentalized and/or reactive focus on data with little focus on uniform data governance. End-user departments just want the source data.
Key reasons businesses model their data warehouse using an industry (canonical) model:
- Perhaps because of acquisitions, there are multiple sources of record (operational systems) for the same data entities, for example, data must be integrated from multiple active ERP systems.
- The principal source of record is very de-normalized but supplies many data entities (e.g. mainframe files like VSAM or IMS).
- In both cases above, a canonical model is needed to provide a consistent interpretation of the source data for consumption.
- The organization has more of a data governance focus (maturity), and is using the canonical model to implement standardized data definitions.
There is an intrinsic design relationship between your central data warehouse and your semantic layer; you need to understand this relationship. If you want integrated data, data discipline has to be imposed at some stage – typically either entering or exiting the central layer. Thus, the more your central data warehouse is modeled after the system of record, the more sophisticated your semantic layer should be. Since there has been little transformation of source data up front, the burden of deciphering, cleansing and standardizing source data values occurs as it is consumed from the data warehouse. Hopefully, that transformation has been standardized in either a series of semantic database views implemented on top of the data warehouse tables or in the BI tool’s semantic layer. Otherwise, each end user of the data warehouse probably has specific (and probably different) methods for accomplishing that transformation, using various end-user oriented tool sets, which will all need to be evaluated for the conversion. Conversely, the more your central data warehouse is modeled using a canonical model, the less sophisticated your semantic layer needs to be. While there may be database views that are used for access control, row level security or multi-tenancy requirements, it would be expected that the database tables in a canonical model essentially meet the consumption requirements. The transformation of source data – deciphering, cleansing and standardizing – should occur as data is loaded into the canonical model. You may still have a semantic layer that focuses on ease and consistency of use, perhaps projecting the canonical model as a star or snowflake schema and resolving typical effective-date filters. Look for this layer to be implemented either as database views or within your BI tool.
At the end of this analysis of your central DW layer, you should clearly understand the strengths and weaknesses of your current implementation style, and understand whether that style is likely to meet your current and foreseeable-horizon business requirements.
Semantic layer
A semantic data model (SDM) captures the business view of information for a specific knowledge-worker community or analytic application. It provides a consistent, governed, intentional view of the data for a group of consumers, typically masking the complexity of the physical representation of the data to make it easier and less error-prone to consume. There may be a different semantic data model for each department/application that uses the data warehouse. One way to look at your semantic layer is as a formal representation of the metadata that gives defined, consistent meaning to the data elements that populate your warehouse.
Semantic data modeling is a logical data modeling technique. The prevalence and intuitive nature of dimensional modeling makes it particularly well-suited to, and commonly encountered for, the semantic data model for an analytic application. In Teradata implementations, the semantic data model will typically be physicalized using either database views or the semantic capabilities of the BI tool; the platform’s data-retrieval engine typically supports efficient access to the central layer without physicalizing an intermediate star schema. In contrast, in a full semantic layer implementation, the data warehouse itself is never directly accessed by downstream applications.
The semantic layer can provide data cleansing, and apply business rules, de-normalizations, transformations, and/or calculations before exposing data for downstream applications.
When considering conversion to the Google cloud, it is important to understand how the semantic layer has been implemented, and the extent to which it is used:
- How much end user access is performed without the semantic layer?
- Has the semantic layer data model been maintained?
At the end of this analysis of your semantic layer, you should know whether the semantic layer or the central data warehouse layer is carrying the bulk of the burden of integrating and standardizing your data. You should also have a good idea how much of the consumption of data from the warehouse goes through governed channels, and how much makes an end-run around your best efforts to standardize.
⇒ Start looking ahead
These are the highlights of the typical implementation patterns we see for Teradata data warehouses. This overview should give you a good start in understanding where your own data warehouse fits into the grand scheme – what patterns it follows, how consistently it has been implemented, and how effective it is in supporting consumers, integrating data from disparate sources, and standardizing data to a consistent “enterprise view”. You are probably starting to get a sense for how much work a conversion to the cloud is likely to be.
⇒ What’s next?
In our next article, we’ll discuss the process of articulating a reference architecture that enables your desired future state environment. That architecture will:
- be justified back to the original implementation and new business requirements;
- be logical only, without regard to specific Google Cloud Platform or other vendor products;
- establish a basis for a single version of the truth;
- establish a basis for data quality and data auditability;
- be layered, with each layer having a clear purpose, contract, and performance expectations.
Consider whether new business requirements should be considered, e.g.:
- Need to support rapid data analysis or agile BI;
- Need to intermingle structured and non-structured data.
Again, we’ll focus on the three architectural layers of the warehouse in turn. Highlights:
Source data capture: You want a consistent architectural design for source data capture and retention. Keep most of your current source data capture processes in place. Reconcile your source data capture layer with any data lake initiatives you may have implemented or been considering. (See article Article 2: Source Data Capture)
Central data warehouse: Identify any specific business requirements that would require a central data warehouse implementation in Google Cloud. Understand any ACID requirements for updates. Reconcile your data warehouse with any MDM initiatives or implementations.
Semantic layer: You want a formal (logical) semantic layer in your architectural design that’s linkable to your business glossary and other data governance artifacts. This will be the basis for the physical implementation of your consumption layer on Google Cloud.
This analysis is the basis on which you’ll determine the cost, timeline and project approval model (including ROI) for a migration to the cloud.
After that, we’ll dive into specific migration patterns.